Author Archives: dp
Jobs in Kharkov V. 3.0
Great news: new version of the Jobs in Kharkov portal launched!
Jobs in Kharkov is the number one web and mobile app for job search and recruitment in Kharkov — the second largest city in Ukraine over 1.5 million in population. With more than 220 000 registered users, this is the most popular regional job search website in Ukraine.
Jobs in Kharkov is Screen Interactive’s own project. We’ve been working on it for many years, and this is the first time it is being completely redeveloped from the ground up. This is a custom made portal with multiple user roles, dozens of pages, and tons of features (only some major ones actually mentioned in our portfolio and the case study).
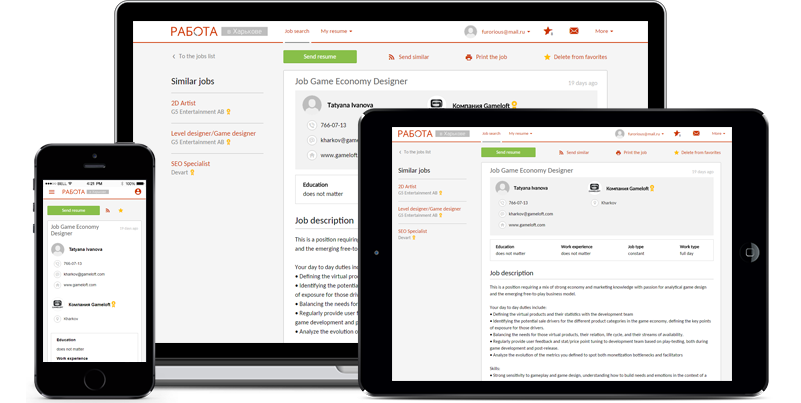
Quite a job to be proud of.
Find out more about the project:
- –
Jobs in Kharkov in our portfolio.
- –
Create a CV using your LinkedIn user profile
A new option is available on our job search website Jobs in Khrakov. Users now can create their CVs using their LinkedIn profiles.
![]()
The user just needs to hit the button marked «Fill in from LinkedIn,» enter his/her social network username and password, and all the information available from the profile automatically fills into the CV creation form. Then select a job category, where to post the CV, edit the text if necessary and publish the new CV.

The website receives all user data through the LinkedIn API.
Jobs in Kharkov is the first job-seeking website in Ukraine that allows users to create CVs using their LinkedIn profiles.
Statistics module for Persia applicant tracking system
One of the important parts of our everyday work is to solve different technical tasks. So, we think we shouldn’t ignore this topic in our blog. Today, we tell you about the Statistics module in the Persia project (the web-service for automating employee recruitment). Persia is a SaaS project created by Screen Interactive.
The task
One of the stages of Persia development was to create a system that will collect, store and display statistical data about a recruiters’ work within a particular company. The company director should know the performance level of his recruiting team, and this data should be based on figures showing the work assessment of the whole company and each employee in particular. In Persia such figures are number of closed vacancies, average time to close vacancy, number of added CVs, average values of these metrics (for a period, for one user), etc.
It’s obvious that some data gets changed or even deleted during the working process. It’s impossible to receive the information about a user’s actions in a previous month using only the company’s actual data stored in the database. So, we decided to collect and store all the information about main user actions in the database.
Searching for a solution
Option A: complete log of all the history
Let’s assume that we store all the history in the database: Information about each user’s separate, definable action is a separate record. It’s clear that with time the statistics table will increase and, as a result, the queries will take too long.
Let’s estimate the speed of the statistics table growth for one user. Suppose that the user adds one resume every minute (which is unrealistic but is clear for analysis). Another user’s operations require even more time to complete. So, we will have 60×24×365 = 525,600 user actions for a year and the same number of records in the statistics table. Now let’s multiply this figure by the number of users in one company, then multiply by the number of companies. A bit too much, isn’t it. What solution do we have? We can separate the statistical information for each company and store it in different tables. That’s acceptable for small companies if they have two or three recruiters and the work is slow-paced. However, the statistics table for big companies is still too large.
Option B: Aggregated data storage
Let’s look at the collected data more attentively and analyze the way we show this information to users. In this case, the user is more interested in the number of the actions completed during a particular period rather than in records of particular actions themselves. So, to choose the minimal time gap, we can store the number of actions as one record. This will essentially reduce the size of the company statistics table. Which minimal time gap to choose? Logically, the statistical data changes rapidly during the working day, and there’s no need to trace it in real time. We suppose that the company director prefers to receive weekly or monthly reports from which he can then make decisions. That’s why we chose one day (24 hours) as a minimal time gap. This will help us get the information with a good level of details.
Using this approach, we receive the table that contains several records for each single day: one row is for the company and one for each recruiter. For example, if a company has two recruiters, the table will have 2×3 х 365 = 2190 records per year. For one user this is 480 times less than in the previous example!
The solution
We created a temporary table common for all companies to collect the information about users’ actions. The data about all activities of all users from all companies during the day go into this table. After that the software executes a special script: it calculates statistical data for each company and saves these figures into the company’s main statistics table. The program deletes the previous day’s records from the temporary table, so the table always has a reasonable size.

Such an approach to gathering and storing the statistics helps to significantly reduce the amount of stored information and increase the speed of receiving the statistics and displaying them to the user.
What users see:

The general statistics for a company

Recruiters’ work stats
Conclusions
Of course, such an approach has its advantages and disadvantages.
Disadvantages:
- –
Information about each single user action is not saved.
- –
It’s impossible to recount the statistics.
- –
Users don’t see the statistics for the current day.
Advantages:
- –
Statistics are saved separately and don’t depend on the changes in main database (even if the initial information is already deleted).
- –
The amount of the stored information is significantly reduced without losing its value as statistic data.
- –
The load on the database server is reduced.
- –
Users can get statistical data faster.